





所有平台仅提供服务对接功能,所载文章、数据仅供参考,股市有风险,投资需谨慎,用户需独立做出投资决策,风险自担!

时间:2022-06-26 13:03:28来源:网络整理
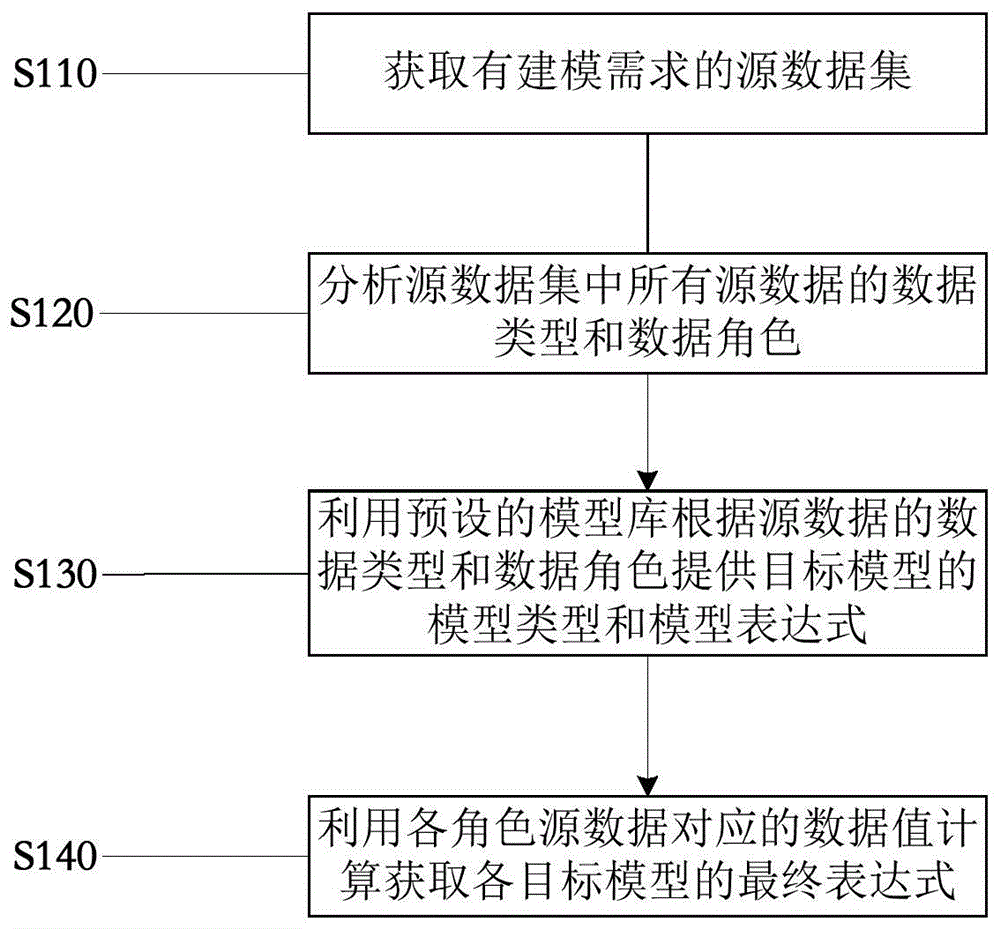
基于Spark平台的数据挖掘技术分析文档信息文档编号:Wen-04T6MJ(自定义文件号)文档名称:基于Spark平台的大数据挖掘技术分析.doc文档格式:Word(*.doc,可编辑) 文档字数:3469 字,(不包括页眉、页脚、版权声明等) 文档主题:这是《IT 计算机》中关于“数据挖掘和模式识别”的参考示例文档,仅供学习和交流之用。不要商业化。 Catalog 基于 Spark 平台的大数据生态系统1.1 Spark Runtime 1.2 Graph 1.3Spark Streaming 基于Spark 平台的开发环境及分布式集群搭建2.1 硬件系统要求< @2.2 构建分布式Spark集群2.3 配置Spark IDE开发环境 基于Spark平台的Apriori算法分布式实现3.1 概述3.2 基于Spark平台的Apriori分布式实现基于Spark平台的算法分布式协同过滤推荐实现4.1 MLIib算法库4.2协同过滤算法正文 李彦宏 摘要:因为大数据有其独特性,即数据量是大且具有突出的多样性,因此在进行大数据分析时,对处理速度、效率和实时性的要求非常高。
数据挖掘技术主要是基于建模算法从大量数据中找出隐藏在数据中的信息,从而促进大数据的价值得到充分利用。 Spark平台是面向大数据集的低延迟集群分布式计算系统,在大数据挖掘和分析方面更有优势。据此,本文主要对基于Spark平台的大数据挖掘技术进行详细分析 关键词:Spark平台 大数据挖掘技术 数据分析 中文图分类号:TP311 文档识别码:A 文章编号:1672-3791(201 8)09(c)-0007-02 基于Spark平台的大数据生态系统1.1 Spark Runtime Spark Core包含的功能主要包括任务调度和内存管理,包括故障系统恢复和storage 系统中相互交互的对应子元素,Spark使用RDD结构传输和打包数据时,需要对Spark的核心逻辑数据信息有一个大致的了解,这样的数据类似于对象的概念在一定程度上,首先将所有数据集划分为若干个子集,每个子集可以传输到集群中的任意节点进行处理。其次,计算的中间结果n 可以很好地保留,基于可靠性考虑问题,可以得到相同的计算机结果并存储在子集中。节点的文件内容。同样大数据挖掘分析平台,如果任何数据子集在计算过程中出现错误,则必须重新排列子集以实现容错机制。
1.2 Graph是Spark中的重点子项目,需要基于Spark构建。在大规模图计算的基础上,由于 Graph 的衍生,Spark 生态在处理大图时可以更加高效。丰富的计算能力,在与其他相关组件系统集成的基础上,利用强大的数据处理能力,实现多场景下的所有应用。 Graph的作用是提供非常丰富的图数据算子,因为类库定义太多了大数据挖掘分析平台,主要包括核心算子和优化算子,还有一部分是在Graph Ops算子中定义的。使用 Scale 隐形语言转换特征时,可以调用 Graph Ops 运算符。在Graph中,可以基于多个分布式集群进行图操作,API接口就足够了,尤其是在达到一定的图规模后,需要一个精益算法,以方便使用分布式图集进行大规模处理。 Graph的优势在于可以有效提高数据吸收和规模。 1.3 Spark Streaming Spark系统是Spark Streaming分布式数据处理的框架系统。在扩展Spark数据能力的基础上,促使Spark Streaming数据流严格按时间划分单元,形成RDD,时间量少。流数据的间隔处理受到处理延迟条件的阻碍,在一定程度上可以看作是一个准实时处理系统。
Spark Streaming 是一个容错性极强的系统,具有非常高水平的错误处理和恢复,因此在处理错误方面具有明显的优势。另外,Spark Streaming可以与相关的Spark生态模块无缝对接,一起完成流数据后,还可以处理一些复杂的现象。基于Spark平台的开发环境及分布式集群搭建2.1 硬件系统要求为保证更好的兼容性和可操作性,搭建Spark分布式集群的物理主机应使用Linux操作系统。选择一台主机的三个虚拟机进行环境测试,并据此搭建一个Spark分布式集群,主要包括两个Worker节点和一个Master节点。其中Master的主要任务是在单机上编写和调整Spark分布式应用,配置比较高。 Master节点机器配置为4G内存和四核处理器,Worker节点机器配置为2G内存和双核处理器。每个节点的硬盘都是基于PCIE的SSD固态硬盘,读写效率高,可以在很大程度上保证运行速度和工作质量。集群的形式不仅可以降低运营成本,还可以根据需求对节点数量的增减进行适当的调整。 2.2 构建分布式Spark集群,首先要安装Scala语言,每个虚拟机的slaves文件内容修改为集群中worker节点的主机名,Spark-节点的Spark安装目录下的env.sh也要修改。文件。
配置系统的jdk环境变量,修改后系统的Scala安装路径为Scala-Home。集群中 Master 节点的主机名和 IP 地址使用 Spark_Master_IP 属性值,其他选项默认。同时需要保证Spark-env.sh文件的内容与集群中所有节点的Slaves文件的内容高度一致。完成配置后,使用 jps 命令查看集群启动状态。 2.3 配置Spark的IDE开发环境 IDEA是Scala语言的开发环境,也是重要的基础,所以作为Spark应用程序的编程开发环境。但为了防止IDEA在使用中产生过多的缓存文件,占用大量空间,消耗I/O资源,文件存储应选择SSD固态硬盘,以保证良好的性能。 IDEA配置完成后,就可以开始测试Spark程序了。基于Spark平台的Apriori算法分布式实现3.1 概述Apriori算法是一种基于挖掘关联规则的频繁项集算法,可以反复扫描事务数据库,利用候选频繁集生成频繁集。主要过程是定义最小支持度,选择所有频繁项集,并根据置信度生成关联规则。 3.2 基于Spark平台的Apriori算法分布式实现基于Spark平台的Apriori算法分布式集群的具体流程如图1所示。
算法的具体思路如下:首先,生成频繁项集,将事务集以RDD的形式分布在每台机器上,累积项数,保留特定支持度较高的项集。其次,从频繁项集中导出频繁项集,项集自连接生成Ck+1,然后扫描数据库,根据C+1生成频繁项集。基于Spark平台的分布式协同过滤推荐实现4.1 MLIib算法库 因为机器算法的过程非常复杂,所以在进行迭代计算时,任何计算都需要放入磁盘,等待任务启动,但是这样会消耗大量的CPU。对此,在使用Spark时,可以将部分工作直接运行在内存中,将部分迭代计算任务转移到内存中,从而提高迭代计算的水平和效率,还可以在进行磁盘和网络操作的时候进行必要的。因此,Spark 在迭代计算方面具有很大优势,也可以发展成为分布式机器学习平台。从通信的角度思考,Spark 优秀高效,通信效率非常高。在进行分布式机器算法学习时,部分资源集中在各个集群节点,良好的通信效率可以进一步保证分布式算法的运行效果。 4.2 协同过滤算法 所谓协同过滤算法,其实就是人们在使用的时候,会选择一个靠谱的想法,然后把这个想法提供给用户。系统过滤在用户中选择兴趣爱好相近的用户,根据喜好选择项目,并组织成新的集合或序列。
用户可以直接定义为邻居,但这个过程的核心问题是,如果用户之间有相似的约定,如何组织和利用符合相关条件的用户。协同过滤的核心思想协同过滤的核心思想需要通过三个步骤来实现,即收集用户兴趣和偏好,详细分析用户使用物品的相似度,并基于计算进行推荐系统推荐效果的关键影响因素是用户兴趣的融合。因为不同用户提供的偏好也大相径庭,而且还受到各种场景的影响。在一般情况下,应该根据用户行为选择和分组用户系统。分组方式主要有两种:一是根据不同的用户行为进行分组。其次,根据不同的行为对用户的爱好进行分组和加权。综合收集数据行为后,进行数据预处理。在此基础上,根据用户的兴趣爱好,向用户推荐可能喜欢的物品,并采用一定的推荐方法,将协同过滤分为两类:基本用户协同和基于物品的协同。在推荐中,选择了最合适的邻居。最常用的方法是固定邻居的数量并指定邻居相似度的阈值。总结一句话,在Yam上部署Spark集群后,不仅可以为算法实验提供良好的测试环境,还可以以线性方式适当扩大集群规模,实际应用到企业生产中。通过将Spark和MLIib有机结合,在分布式集群中制定分布式协同过滤推荐操作方案,并基于大数据集进行验证,可有效应用于大量推荐系统。
另外,基于Spark平台的分布式Apriori算法在很大程度上弥补了MLIib中关联分析算法的缺陷,可以有效地应用于大数据的关联分析。参考文献[1]曹孟.基于Spark核心架构的大数据平台技术研究与实践[J].中国战略性新兴产业,2018(28): 130, 132. [2] 孟雅格. 基于 Spark 平台大数据推荐系统研究[D]. 西安电子科技大学, 2017. [3] 何美斌,胡晶晶. 基于Spark的大数据分析平台设计[J]. 电子技术与软件工程, 2016(21): 184. [4] 邢英军. 基于Spark的大数据挖掘技术研究[J]. ]. 计算机知识与技术, 2017, 13 (16): 19-20. 《基于Spark的《大数据挖掘技术分析》文档来源于网络,本人编辑整理。基于出于保护作者知识产权的原则,仅供学习交流,不得用于商业用途,将尽快删除,感谢您的阅读和下载!
声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。








图文推荐
2022-06-26 12:04:38
2022-06-26 11:00:32
2022-06-26 10:01:35

2022-06-26 09:01:30

2022-06-25 13:01:07

2022-06-24 11:01:07
热点排行
精彩文章
2022-06-26 11:00:48

2022-06-26 10:02:32

2022-06-26 10:01:21

2022-06-26 09:01:13

2022-06-25 09:02:20

2022-06-24 13:00:37
热门推荐
