





所有平台仅提供服务对接功能,所载文章、数据仅供参考,股市有风险,投资需谨慎,用户需独立做出投资决策,风险自担!

时间:2022-07-16 09:00:17来源:网络整理
【摘要】 随着信息网络应用的普及,用户通过社交网络参与各种信息的交流、发布和交换,这些海量信息的交换和发布为情感分析提供了可能。本文中的情感分析主要限于社交媒体数据的情感取向分析或情感分类。社交网络数据主要以文本形式存储,其文本短小精炼,特征稀疏用户情感分析框架,语义复杂。这类信息的一般做法是将单词作为维度进行分析,从而忽略了文本中单词之间的关系。本文主要提出两种基于微博和维基百科中英文语料的情感分析方法:1)针对微博中文语料,在加权word2vec模型的基础上提出加权doc2vec模型,可以直接训练句子向量,省略了将词向量转换为句子向量的步骤。主要思想是将TF-IDF算法和预训练的词向量结合起来,使用TF-IDF算法对学习到的词向量进行加权,然后将它们作为doc2vec模型的输入来重新训练句子向量。在实验中,与其他情感分析方法相比,可以看出这种处理方法在实验中表现更好。 2)针对维基百科英文语料库,主要在doc2vec模型的基础上引入关系信息模型,提出关系信息句子向量模型(RISV)。两者共享词向量。训练时,doc2vec模型用于训练句子向量,而关系信息模型用于训练词的关系信息。组合之后,相当于在doc2vec模型的训练中加入了关系监督信息。该模型增加了一个权重参数来平衡两者对句子向量学习的影响。最后,在文档分类任务和短文本语义相似度任务中验证了学习到的句子向量的有效性。实验结果表明,RISV模型在这两个任务上比传统的情感分析方法更有优势。最后,本文提出了两种情感分析方法的预训练方案。预训练的使用为句子向量的训练带来了类似于先验分布的正则化。使用RCM模型作为预训练模型用户情感分析框架,也在一定程度上补充了关系信息的知识。在训练过程中,预训练模型与句子向量训练模型共享词向量和参数。在实验中可以发现,预训练可以提高实验性能,但是训练对任何任务都没有效果,特别是对于一些层数低、节点少的网络,提升幅度不大。
声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。








图文推荐

2022-07-15 12:01:25
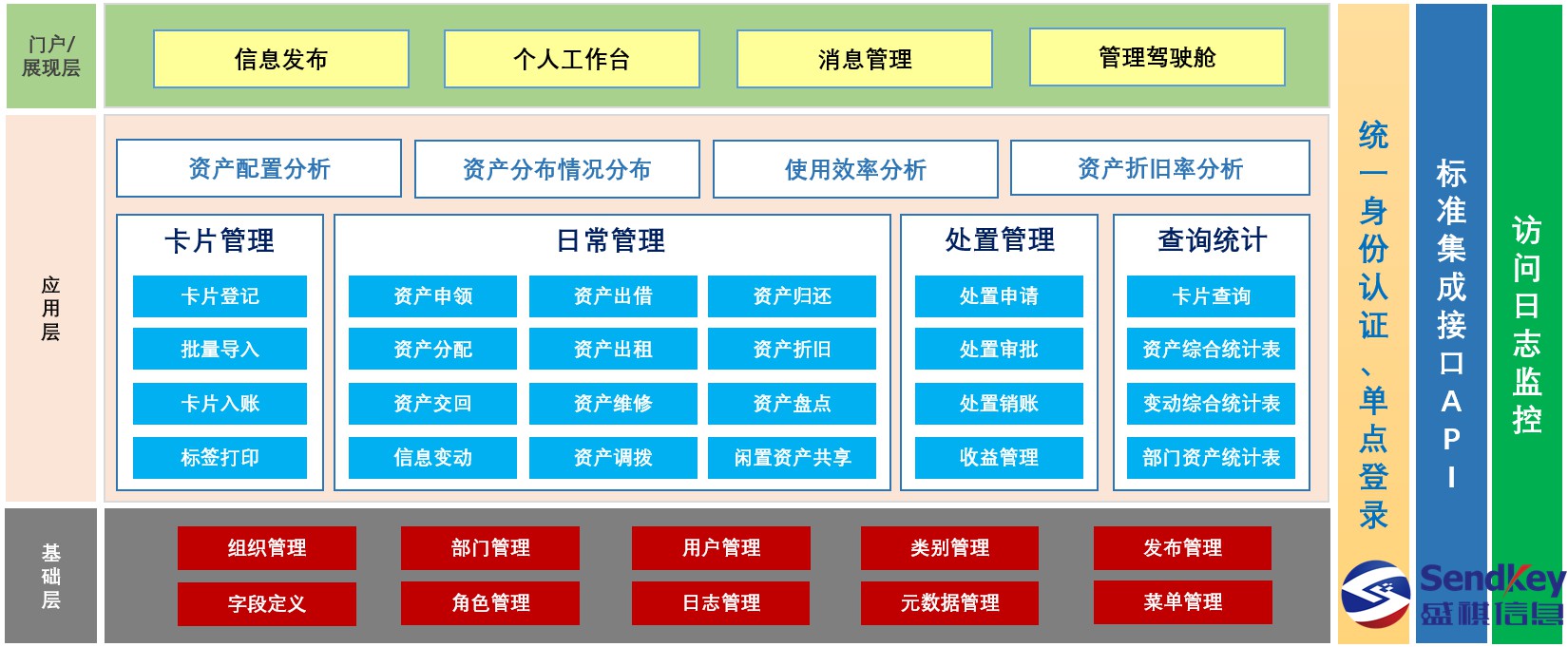
2022-07-15 09:01:15

2022-07-15 09:01:07
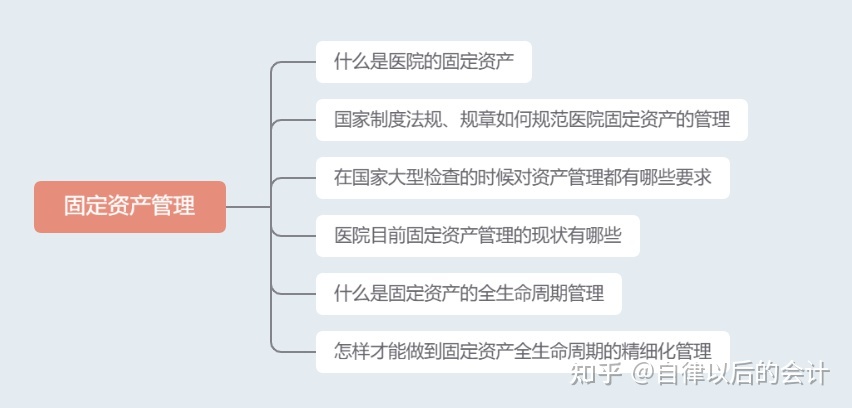
2022-07-14 14:00:49

2022-07-14 13:02:42

2022-07-14 09:03:16
热点排行
精彩文章

2022-07-14 11:08:26
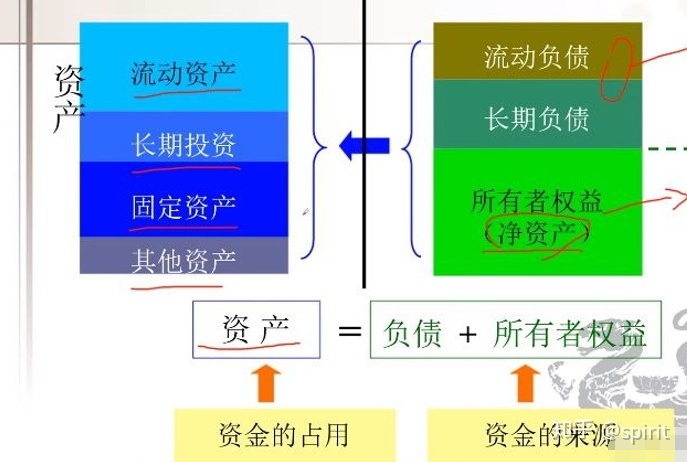
2022-07-14 11:07:29
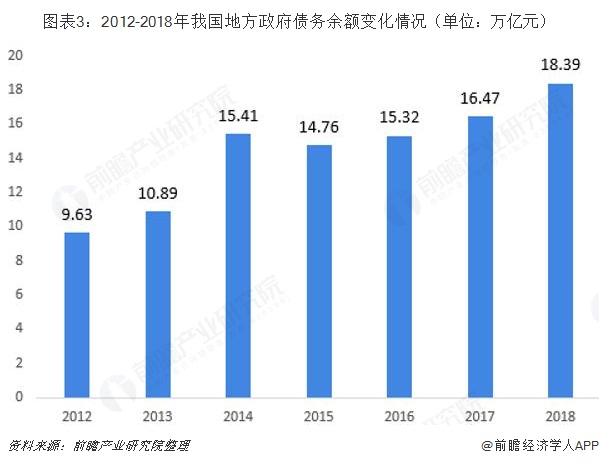
2022-07-14 09:05:41

2022-07-13 14:35:56

2022-07-13 14:34:27
2022-07-13 09:05:24
热门推荐
